
Chisel Sharpening: In the end, it's all about results
29 Aug 2017 At the end of the day, it's all about results, of course. A productivity improvement is great, as long as the implementation results at least stay constant. Any decrease in implementation results definitely detract from any productivity improvements.So, after all the work thus far describing and verifying the wishbone interconnect, we still have to answer the question: how are the results? How does the Chisel description compare, in terms of synthesis results, to the results from the hand-coded description?
In this post, I'll be using Intel/Altera Quartus for synthesis (since I have access to an Altera prototype board and Quartus). If anyone wishes to donate a Zynq prototype board, I'd be happy to report the results from Xilinx Vivado as well.
There are two things that we care about when it comes to implementation: speed and size. What's the maximum frequency at which the implementation operates? How many logic elements are required? How many registers?
Prerequisites
Synthesis tools are very good, by design, at eliminating unused logic. Any I/Os in our design that aren't connected will be optimized out of the design. Consequently, synthesizing the interconnect will only work under two conditions: if all the interconnect I/Os are connected to FPGA device I/Os, or if we build a design around the interconnect that utilizes the all the interconnect I/Os.
Given the number of I/Os the wishbone interconnect has, the second path is the most feasible.
We already have a synthesizable Wishbone target memory device from the verification environment. Now, we just need something to drive the master interfaces. Just to further explore Chisel, I created a Wishbone initiator using the LFSR Chisel module to randomize the address (to select the target device), read/write, and write data.
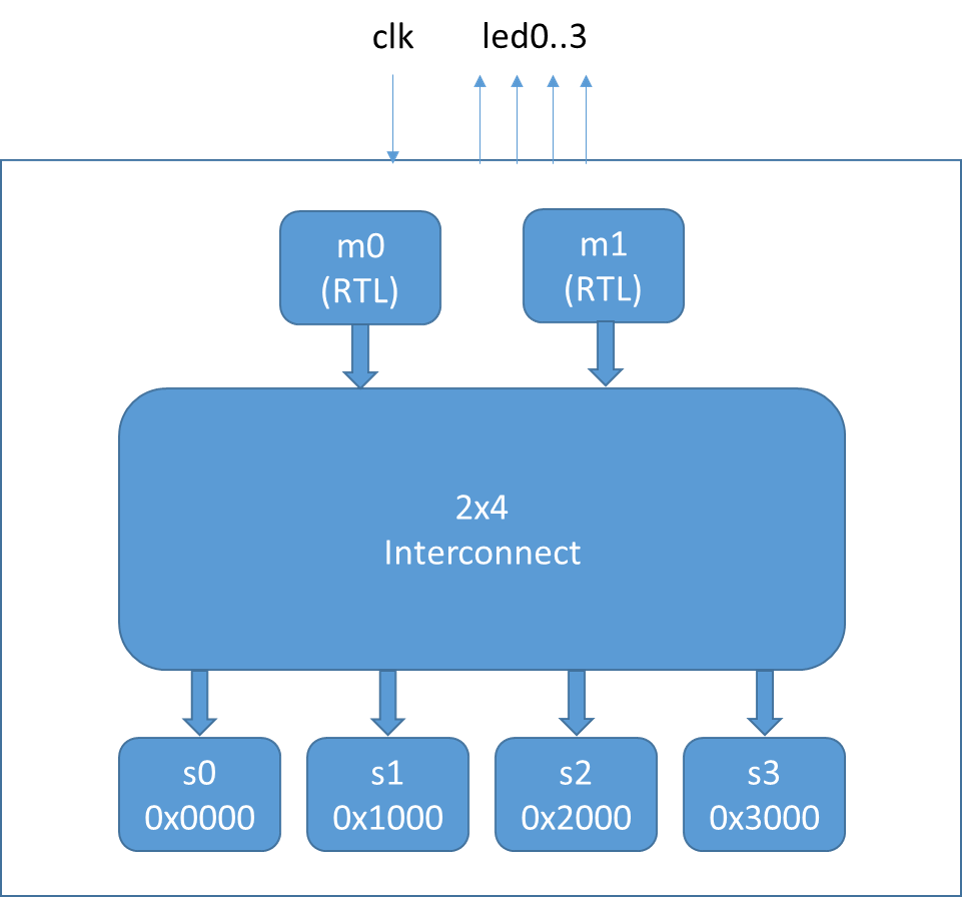
I connected up the LEDs to counters that toggle the LED every time the respective target device is accessed 16,384 times -- just for kicks, and because I like blinking lights...
Results
For comparison, I'll leave everything the same about the design except for the interconnect. Here are the relevant details:
| Design | Registers | ALMs | Fmax |
|---|---|---|---|
| Hand-coded | 264 | 239 | 160.64 |
| Chisel | 227 | 275 | 201.37 |
So, Chisel uses:
- 14% more ALMs than the hand-coded RTL
- 14% fewer registers than the hand-coded RTL
So, it's a bit of a wash in terms of size.
The performance difference is fairly significant, though: the Chisel design is 25% faster than the hand-coded RTL. So, the (slightly) higher-level description certainly doesn't hurt the results! Now, I'm sure I could achieve the same results with the hand-coded description that the Chisel description achieved. I'm still a bit surprised, though, that the Chisel description achieved better results out the box with a less-than-expert user. So, definitely a promising conclusion to my initial Chisel exploration!
Now, just for fun, here is the design running on the Cylone V prototype board.

Stay tuned for more details on what I'm learning about Chisel constructs. And, you can find the code used in my experiments here: https://github.com/mballance/wb_sys_ip