
Python Verification: Working with Coverage Data
26 Apr 2020
Before jumping into this week's post, I wanted to offer a bit of an apology to my readers. I recently realized that, despite being a Google property, Blogger only notifies authors of comments for moderation if the author has specifically registered a 'moderator' email with the site. So, apologies to those of you that have commented on posts directly on the Blogger site and watched those comments hang out in limbo indefinitely. I should now receive notifications of new comments.
In my last post, we looked at modeling and sampling functional coverage in Python using the Python Verification Stimulus and Coverage (PyVSC). In that post, I showed how a textual coverage report could be generated to the console by calling an API. But, there is much more that we want to do with functional coverage data. The key question is: how do we store and manipulate it?
Storing Coverage Data
There are two big motivations for storing coverage data. The first is that we often wish to aggregate coverage across a large number of tool runs. In order to do that, we need a way to persist the coverage data collected by each individual tool run. The second is that we want to run analysis on the collected and aggregated coverage data. We want a way to browse through the data interactively, and create nice-looking reports and charts.
Standard Coverage Models
Storing coverage data isn't much different than storing any other data. The first big question to answer is whether there is a standard way of of representing the data, or whether we need to invent one. While I've certainly had fun in the past inventing new formats for representing and storing data, considering all the requirements and designing in appropriate features to represent all the key features of a given type of data is a time consuming problem. Certainly something that should be undertaken as a last resort.
The good news is that there are several existing formats for representing coverage. The bad news is that the vast majority are focused on representing code coverage data (eg Coburtura), not functional coverage data. That said, there is one industry standard for representing functional coverage and code coverage: Accellera Unified Coverage Interoperability Standard.
While the UCIS defines several things, it doesn't define a standard database format. That said, what it does define is very useful. Specifically it defines:
- A data model for representing functional coverage, code coverage, and assertion coverage
- A C-style API for accessing and modifying this data model
- An XML interchange format to assist in moving data from one database implementation to another. In a pinch, the XML interchange format can even be used as a very simplistic database.
Design is tough, so it's almost always most efficient to make use of the work of a committee of smart and capable people instead of starting over. UCIS is certainly not perfect. There are some "bugs" in the spec, and some internal inconsistencies. That said, it's far better than starting with a blank sheet of paper. The next challenge was adapting UCIS to Python.
PyUCIS Library
Much of my work recently has been in Python, so I wanted a way to work with the UCIS data model in Python. The PyUCIS library is a pure-Python library for working with the UCIS data model. A block diagram of the architecture is shown below.

Front-End API
The core of the PyUCIS library is an implementation of the UCIS API. Remember that the API defined by the UCIS is a C-style API, while Python is much more object-oriented. I initially decided to implement just an object-oriented version of the UCIS API, but then realized that reusing existing code snippets written in C would be much harder without an implementation of the C-style API. Fortunately, building a C-style compatibility API on top of the object-oriented one was fairly straightforward.
Backend
The PyUCIS library uses a back-end to store the data being accessed via the front-end API. The PyUCIS library currently implements two back ends: an in-memory back-end, and an interface to existing C-API implementations of the UCIS API.
The in-memory back-end stores coverage data in Python data structures. While it's not possible to persist the data model directly, the contents can be saved to and restored from the XML interchange format specified by the UCIS.
The C-library back-end uses the Python ctypes library to call the UCIS C API as implemented by a tool-specific shared library. This allows PyUCIS to access data in databases implemented by tools that support UCIS.
While PyUCIS doesn't currently implement its own native database for storing coverage data, it's likely that it will in the future. Fortunately, Python provides an SQLite database as part of the core interpreter installation. Stay tuned here.
Built-in Apps
The final part of the PyUCIS library are a set of built-in apps. These are used to perform simple manipulations on the coverage data and create outputs. Currently, PyUCIS only contains one built-in app: reading and writing the UCIS XML interchange format. That said, there are a couple planned on the roadmap:
- A merge app to combine data from multiple UCIS data models
- A report app to produce a textual or HTML coverage report
PyUCIS Apps
The top layer of the PyUCIS architecture diagram are external applications that use the PyUCIS API. At the moment, there is only one and it's a proof of concept. PyUCIS Viewer is a Python Qt5-based GUI for viewing coverage data.
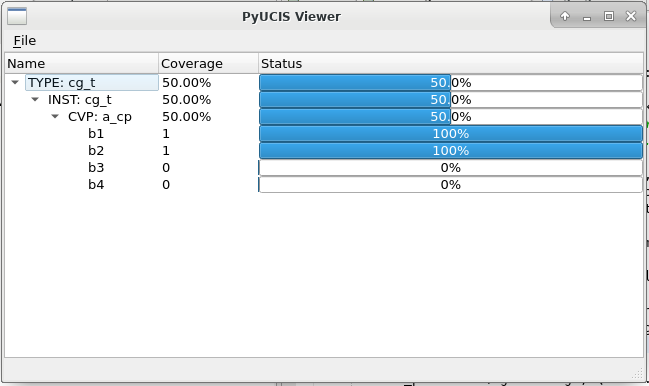
While the viewer is certainly primitive (and incomplete) at the moment, hopefully this provides some ideas for what can be done with the data accessed via the PyUCIS API.
Next Steps
PyUCIS is a pretty early-stage tool. I'm using it to save coverage data from the PyVSC library, and to produce some simple text coverage reports, but there's still quite a bit to do. As always, if you'd like to contribute to this or other projects, I'd welcome the help.
In the next post, I'll return the Python Verification Stimulus and Coverage (PyVSC) library to look at modeling constrained-random stimulus. Until then, stay safe!
Disclaimer
The views and opinions expressed above are solely those of the author and do not represent those of my employer or any other party.