
Relating Actions with Dataflow
18 Mar 2023
Modularity and reuse are key concerns when it comes to programming
languages. While languages without many modularity and reuse features may be
quick and easy to write – think shell scripts – they ultimately fail to scale.
PSS provides a wealth of mechanisms for structuring test content for reuse
that are familiar to users of object-oriented languages. That said, PSS provides
unique approaches to modularity and reuse as well. The PSS modeling layer
is strongly declarative,
and this has significant implications on the approach that PSS takes to
provide reuse features for composing declarative behaviors.
In this post, we will start to look at declarative data relationships via the
PSS buffer construct.
Rewinding a Bit…
Recall that, in the last post, we were creating very simple multi-core read/write tests, such as what is shown in the diagram below:
In order for our test to make sense, we needed a few relationships to hold:
- The source address for our Copy address needed to be the same as the destination address of the Write
- The source address for the Check action needed to be same as the destination address of the Copy
- The source and destination addresses of the Copy needed to be different. We didn’t want to clobber our previously-written data until we’ve had a chance to check it, after all.
component memtest_c {
// ...
action WriteCopyCheck {
Write write;
Copy copy;
Check check;
activity {
write;
copy;
check;
}
constraint {
// Copy reads from same location that Write populated
copy.src == write.offset;
// Check reads from the same location that Copy populated
copy.dst == check.offset;
// All actions write the same number of words
copy.words == write.words;
copy.words == check.words;
// Ensure that src/dst regions do not overlap
(copy.src+(4*copy.words) < copy.dst) ||
(copy.src > copy.dst+(4*copy.words));
}
}
// ...
}
In the last post, we took a bit of a shortcut and modeled all of these relationships as data constraints in a compound action. While the code above is perfectly legal and valid in PSS (hopefully you had a chance to try out the example code with a PSS tool), it doesn’t lend itself to reuse. The specific problem is that the Check action has some required data relationships that are not expressed as part of the action. And, the fact that that we’ve built these actions without expressing how they can be related by data means that users will need to dig into the code to understand the internal variables and constraints – clearly not what we expect from modular code.
From Data to Temporal Declarative Relationships
If you’re coming from a SystemVerilog background, data constraints are most likely the declarative programming feature that you’re most familiar with. SystemVerilog supports declarative descriptions with respect to data, but not with respect to time (temporally declarative).
What does this mean?
class my_vseq extends uvm_sequence;
task body();
my_subseq seq1 = my_subseq::type_id::create();
my_subseq seq2 = my_subseq::type_id::create();
seq1.start(m_subsqr);
seq2.start(m_subsqr);
endtask
endclass
The UVM sequence shows two sub-sequences being run sequentially. SystemVerilog
doesn’t provide any features that allow us to directly relate these two
sequences declaratively (ie using constraints) while retaining their temporal
relationship. If we need a data relationship to hold across seq1 and
seq2, then we need to group our two classes together in a larger class,
express the data relationship as a constraint in the containing class,
solve the two sequences together, then deal with selectively executing each
of the sub-sequences in the desired temporal relationship.
It’s certainly not impossible, but can force us into some awkward design patterns of collecting lots of otherwise-unrelated classes such that they can be solved together before separating them to run over time.
Toward a Declarative API
The cross-action constraints that we used in the previous post are one temporally-declarative feature that PSS provides. PSS allows us to express how action execution is related temporally, add constraints on top, and let the PSS tool worry about how to group data and constraints such that both the data and temporal relationships hold over time.
But, PSS goes beyond that as well. PSS provides specific data types for
expressing the way that data that is shared or passed between temporally-related
actions, and specific ways for actions to note when they input (require)
data from other actions and when they output (produce) data for other actions.
We’ll see more details on how this I/O contract for actions helps in the future.
For now, it’s a great feature to assist in making PSS descriptions more modular
and reusable.
Updating the Memory-Test Actions
All of the data relationships in our memory test are between
sequentially-executing actions. PSS provides the buffer data type to express
passing data sequentially between actions. The semantics of a buffer object
match our intuition based on the dictionary definition: it’s a place to store
data produced by one action before being consumed by some other action.
A buffer is a built-in data type in PSS that is a compound data structure.
In other words, it’s like a struct in C/C++ or Rust, and like a class
(but without the methods) in some other languages.
In our application, there are two pieces of data that the actions need agree on: address offset and number of words being copied.
buffer mem_b {
rand bit[32] in [0..0xFFFFFF] offset;
rand bit[32] in [1..256] words;
}
We declare these fields inside a data type of kind buffer to declare our
flow object. Note that these fields are declared rand because the represent
relationships between the producing and consuming actions, and because
we intend to constrain them. We will use that mem_b type
across our Write, Copy, and Check actions to represent data-flow
relationships. When we update our Write
action to use the buffer, we’ll replace the local offset and words
fields with references into the buffer field.
Now, let’s compare the old and new versions of the Write action to see the difference.
Old
action Write {
rand executor_claim_s<core_s> core;
rand bit[64] in [0..0xFFFFFF] offset;
rand bit[32] in [1..256] words;
exec body {
repeat (i : words) {
write32(
make_handle_from_handle(comp.base_addr, 4*(offset+i)),
i+1);
}
}
}New
action Write {
output mem_b dat_o;
rand executor_claim_s<core_s> core;
exec body {
repeat (i : dat_o.words) {
write32(
make_handle_from_handle(comp.base_addr, 4*(dat_o.offset+i)),
i+1);
}
}
}Note that we’ve added an output to the action, and replaced use of the local variables offset and words with references to the fields of the buffer object output. While remaining functionally the same as before, our Write action is now much more specific about its participation in the scenario.
When we depict PSS elements graphically, we show an action’s buffer inputs and outputs as shown below. Note that the output buffer is shown sequentially after the Write action, since it is only available after the Write action is complete.
Okay, let’s update the Copy and Check actions as well. Note that we have moved the constraints that ensure that the source and destination areas do not overlap into the action. This, in addition to using flow objects to relate the actions, helps to keep things modular and encapsulated.
action Copy {
input mem_b dat_i;
output mem_b dat_o;
rand executor_claim_s<core_s> core;
// Ensure we copy the same number of words
constraint dat_i.words == dat_o.words;
// Ensure that src/dst regions do not overlap
constraint (dat_i.offset+(4*dat_i.words) < dat_o.offset) ||
(dat_i.offset > dat_o.offset+(4*dat_i.words));
exec body {
bit[32] tmp;
repeat (i : dat_o.words) {
tmp = read32(
make_handle_from_handle(comp.base_addr,
4*(dat_i.offset+i)));
write32(
make_handle_from_handle(comp.base_addr,
4*(dat_o.offset+i)),
tmp);
}
}
}Our updated Copy action will look like this when we show it in a diagram:
action Check {
input mem_b dat_i;
rand executor_claim_s<core_s> core;
exec body {
bit[32] tmp;
repeat (i : dat_i.words) {
tmp = read32(
make_handle_from_handle(comp.base_addr,
4*(dat_i.offset+i)));
if (tmp != i+1) {
error("0x%08x: expect %d ; receive %d",
4*(dat_i.offset+i), i+1, tmp);
}
}
}
}Updating the Memory-Test Scenario
Now that our actions are updated to capture the data they require and produce, we can turn our attention to assembling a scenario. Recall that our original scenario looked like this, with constraints enforcing all relationships:
action WriteCopyCheck {
Write write;
Copy copy;
Check check;
activity {
write;
copy;
check;
}
constraint {
// Copy reads from same location that Write populated
copy.src == write.offset;
// Check reads from the same location that Copy populated
copy.dst == check.offset;
// All actions write the same number of words
copy.words == write.words;
copy.words == check.words;
// Ensure that src/dst regions do not overlap
(copy.src+(4*copy.words) < copy.dst) ||
(copy.src > copy.dst+(4*copy.words));
}
}Instead of using constraints, we will connect the input and
output buffers on the action together. How to do we form those
connections? The bind statement.
The Activity Bind Statement
The activity bind statement is used to connect action I/O
ports together. In its simplest form, a bind statement
connects a single input and output. For example:
action WriteCopyCheck {
Write write;
Copy copy;
Check check;
activity {
write;
copy;
check;
bind write.dat_o copy.dat_i;
bind copy.dat_o check.dat_i;
}
}In this case, we are specifying that the output of the Write
action and input of the Copy action are connected, and the
output of the Copy action and input of the Check action
are connected.
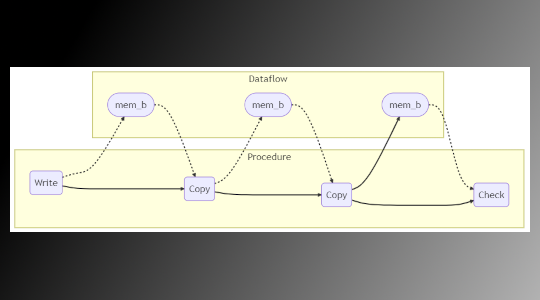
We might visualize this as follows.
We have two views of the scenario. In the Procedure portion we have the temporal relationship between actions (write, copy, check). In the Dataflow portion, we can see the data objects relating various actions.
Extending the Scenario
As mentioned in the beginning of the post, the buffer construct
is a feature that enables encapsulation and reuse.
Let’s leverage that reusability to extend our scenario to see how
this works in practice. Let’s
say that we want to perform two copies back to back instead of a
single one. All we need to do is add in the second copy action
and connect it into the scenario with binds.
action Write2xCopyCheck {
Write write;
Copy copy1;
Copy copy2;
Check check;
activity {
write;
copy1;
copy2;
check;
bind write.dat_o copy1.dat_i;
bind copy1.dat_o copy2.dat_i;
bind copy2.dat_o check.dat_i;
}
}First off, there is a reduction in the number of lines of code required
to setup this scenario compared to what would have been required if we
used plain data constraints. Secondly, input/output ports on actions express the
interface of an action to the outside world. It’s a way for a
library developer (or, just my colleague who wrote some actions) to
express where I should focus as an end user of the action.
Flow-Object Pools and Binding
There is one final thing to be aware of with PSS flow objects, and that
is the pool construct. We’ll largely gloss over it until we hit
cases where we really need to use pools. For now, it’s important to
understand that actions need to be connected to the same pool in
order to be connected via a flow object like a buffer. You’ll often
see code like what is shown below to create a pool for a flow object
type and connect all action I/O references of that flow-object
type to the pool.
buffer mem_b {
rand bit[32] in [0..0xFFFFFF] offset;
rand bit[32] in [1..256] words;
}
component memtest_c {
pool mem_b mem_b_p;
bind mem_b_p *;
// ...
}Wrapping up and Looking Forward
In this post, we looked at the buffer declarative data-flow construct.
We’ve seen how this can help to make our actions more reusable and
better encapsulated. The buffer construct provides a way to relate
actions via sequential data transfer. As you might guess, PSS also
provides similar constructs for enabling actions to be related by
data in other ways. We’ll look at those mechanisms in future posts.
For now, feel free to look at the full code listing and run it through your favorite PSS processing tool. Try adding new constraints on sub-actions within the scenario and try further-expanding the scenario.
If you’re interested in reading more about buffers, pools, and other flow objects, have a look at section 5.1 in the LRM referenced below ([1])
I’m a big proponent of using real-world examples to introduce concepts in a practical context. In the next post, I’ll introduce an example that we will use as a vehicle to introduce the next series of PSS modeling topics.