
Agentic AI has quickly become a dominant workflow. Give an LLM access to the filesystem and shell, provide it good instructions, and watch it work! It’s that second part that is critical to making the process scalable. LLMs are quite happy to fill in the gaps where instructions are incomplete. Agent Skills help make agentic workflows repeatable and consistent.
Reusable is a great start, but making them context-specific – scoped – is just as important. The skills to which an agent has access should be determined by what the current project actually uses. This post argues that the best way to do this is to deliver skills along with the artifacts that they describe.
Agent Skills in one minute
If you’re already familiar with Agent Skills, skip ahead. If not, the concept
is straightforward: a skill is a directory containing a SKILL.md file – a chunk of
Markdown with a little YAML frontmatter that gives the skill a name and a
description – plus any optional scripts or reference files it needs. The
Agent Skills specification and
Anthropic’s skills repository are good
places to see the shape of them.
Skills solve two problems:
- Discoverability. The agent can see, from a short description, that a capability exists without you having to remember to paste in the relevant instructions every time.
- Progressive disclosure. When an agent loads skills, it only reads the description into the context initially. It only reads more of the skill files if and when it decides that the skill is relevant to the task at hand.
Where skills come from today
Most AI assistants – Claude Code, Codex, and others – let you configure skills through the filesystem or through tool commands, with both directory-specific and global scopes supported. The default tends to be global.
The interactive path to acquiring skills is a marketplace. Several have emerged and they’re growing quickly.
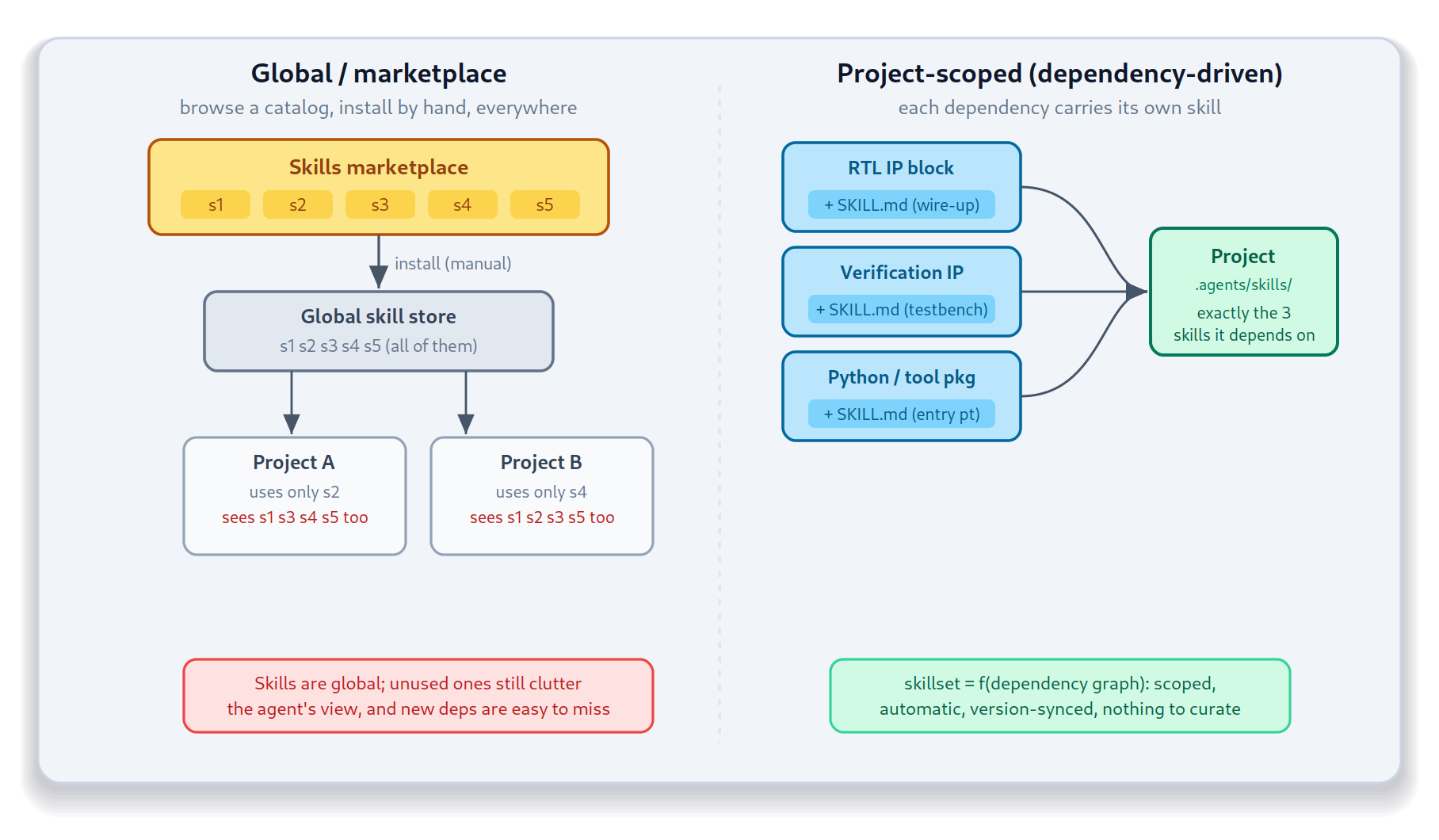
One challenge with the marketplace is that installation and curation are human-driven: you browse a catalog, decide you want a capability, and install it. This makes it available in whichever scope(s) you installed it. But, that either entails having all skills installed always or remembering to install skills whenever you start a create a new workspace.
Skills should travel with the artifact
The person best positioned to write “how to use X” is the author of X. And the most-natural vehicle for shipping that knowledge is X’s own package. This ensures that the skill matches the installed version of X, and gets updated along with the package.
For example:
- A Verilog/RTL IP block can ship a skill that teaches an agent how to wire it up and drive it.
- A verification IP can ship a skill describing how to instantiate it in a testbench.
- A Python package can deliver a skill the same way it delivers any other packaged resource.
In each case the author of the artifact is the author of the skill, and the two stay in sync because they live in the same package. Contrast that with a marketplace listing: standalone, general-purpose, and free to drift out of sync with the thing it describes. When the IP gains a new port or the API changes, the skill that shipped alongside it changes too. A separately curated catalog entry has no such guarantee.
Having skills travel with the artifact provides us a new possibility: to create a project-scoped set of skills that cater to the needs of an engineer developing that project. No need to remember to install skills after setting up a workspace. No potential confusion from skills from a dependency that isn’t relevant to your project.
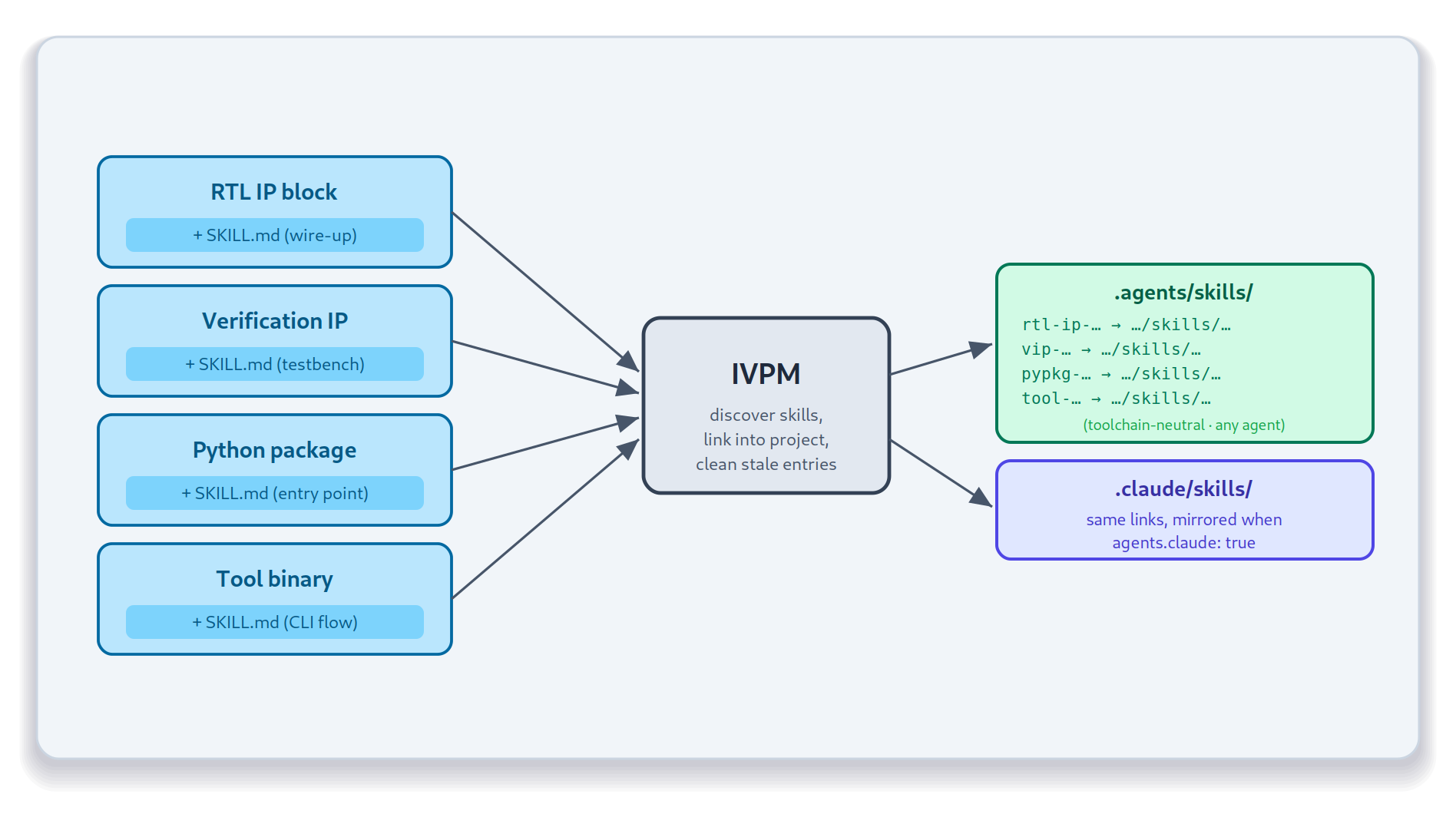
IVPM: project-specific skillsets
That’s where IVPM comes in. The Integrated View Package Manager’s mission is to fetch a project’s dependencies and integrate the relevant content into project-specific views. For example, a project-local Python virtual environment containing the project’s Python dependencies. IVPM does the same for agent skills: it gathers the skills delivered by a project’s dependencies and links them into the appropriate directory-local assistant configuration.
IVPM discovers skills through four mechanisms, applied in priority order:

- Consumer-specified paths. The dependency entry in your
ivpm.yamlcan name a glob (e.g.skills/**/SKILL.md) telling IVPM where the skills live. - Package-declared paths. A dependency can advertise its own skill
locations via
with.agents.skillsin itsivpm.yaml. - Auto-probe. Absent any declaration, IVPM looks for a
SKILL.mdat the package root and searches askills/directory. Most packages need no configuration at all because of this. - Python entry points. For installed Python packages, IVPM queries the
agent.skillsentry-point group, so a package can register its skills programmatically. (A legacyivpm.skillgroup is still accepted for backward compatibility.) Each entry point is a callable that returns a path – or list of paths – to directories containing aSKILL.md.
Once discovered, the skills are linked into your project’s configuration
directories. IVPM always populates .agents/skills/ – the toolchain-neutral
layout that any skills-aware agent can read – and, when you ask for it, also
mirrors into .claude/skills/ so Claude Code picks them up automatically.
Links are relative when the target lives inside the project tree and absolute
otherwise, with a directory copy as a fallback on platforms that don’t support
symlinks. Stale links from previous runs are cleaned up on each update.
The only opt-in is a short block in your project’s ivpm.yaml:
package:
with:
agents:
claude: true # also mirror skills into .claude/skills/
A worked example
You can find a runnable example in the IVPM repository:
examples/agent-skills.
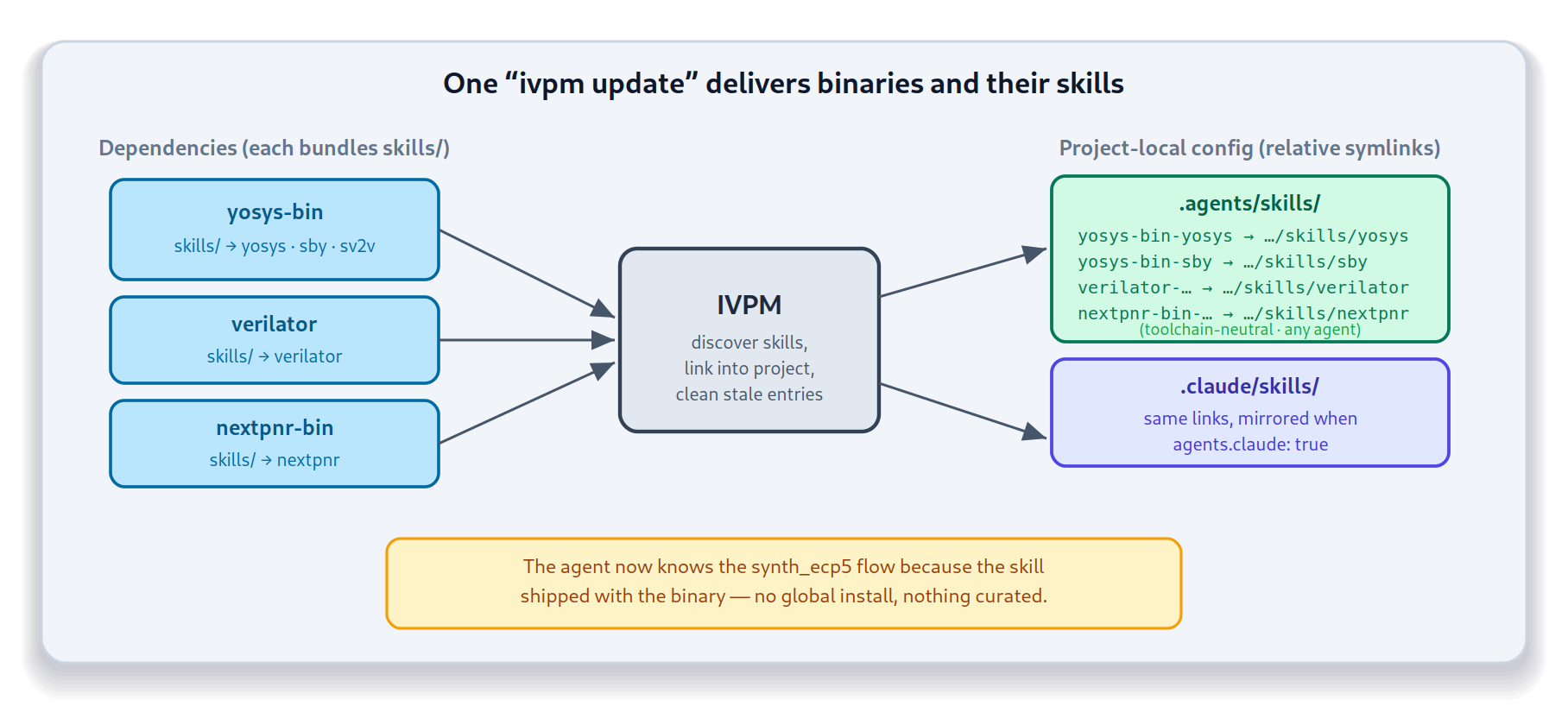
The project depends on three pre-built EDA tools fetched as binary releases
from the EDAPack feed – yosys (RTL
synthesis), verilator (simulation), and nextpnr (FPGA
place-and-route). Each of those release tarballs bundles its agent skills
under a skills/ directory, so IVPM auto-discovers them with no extra
configuration. The project’s ivpm.yaml does nothing more than list the
dependencies and flip on the Claude mirror shown above.
Run a single command:
ivpm update
IVPM fetches the tool binaries and, in the same step, links every discovered skill into the project:
.claude/skills/
├── yosys-bin-yosys -> ../../packages/yosys-bin/skills/yosys
├── yosys-bin-sby -> ../../packages/yosys-bin/skills/sby
├── yosys-bin-sv2v -> ../../packages/yosys-bin/skills/sv2v
├── verilator-verilator -> ../../packages/verilator/skills/verilator
└── nextpnr-bin-nextpnr -> ../../packages/nextpnr-bin/skills/nextpnr
Now open your agent in that directory and ask:
Simulate the blink design and testbench in Verilator, using available skills. Then synthesize the design targeting ecp5 using yosys and nextpnr.
The agent already knows the synth_ecp5 flow, because the skill that explains
it shipped with the synthesis binary. Nothing was hand-curated, and no global
catalog was browsed. One ivpm update delivered both the toolchain and the
know-how to drive it – and the capability tracked the dependency graph
exactly.
Conclusions and next steps
Skills are most useful when they’re scoped to what a project actually uses, and the package manager is the right place to do that scoping. By treating skills as artifacts that travel with the artifacts that they describe, you get a project-specific skillset that’s assembled automatically, stays in sync with its sources, and disappears when its dependency does. No catalog to browse, nothing to remember to install.
If you maintain an artifact that others integrate – an IP block, a tool, a
library – consider shipping a skill alongside it. You’re the person best
positioned to write it, and a skills/ directory is a small thing to add. And
if you’d like to try the consuming side, the
agent-skills example
is a good place to start.